Real-Time Lead Scoring with Enrichment Data: How to Prioritize Inbound Leads Faster

Table of Contents
Explore Bitscale
Find decision makers, more insights and contact information about this company on Bitscale
Inbound lead scoring sounds straightforward until you try to do it in real time. Form fills and demo requests arrive instantly, but the scoring that should tell your reps who to call first? It runs on a nightly sync, depends on fields the prospect never filled in, or sits frozen until someone manually researches the company. By the time a score updates, the lead has gone cold or signed with a competitor. For revenue teams under pressure to convert pipeline faster, this lag is not a minor inconvenience. It is a structural bottleneck that erodes speed-to-lead, inflates cost per opportunity, and quietly drains quota attainment.
This article walks through building an inbound lead scoring system that updates the moment a lead arrives, using enrichment data to fill the gaps a form can never capture. The stack doesn't matter much: HubSpot, Salesforce, or something lighter all work with these principles. The outcomes you're after are faster speed-to-lead, fewer wasted rep touches, a cleaner MQL-to-SQL handoff, and a priority queue that reflects what's happening right now, not what happened last night.
Why Inbound Lead Scoring Breaks the Moment You Go Real Time
The core problem is lag. A prospect submits a demo request at 9:47 AM. Your CRM receives the record. The scoring workflow runs at midnight, enrichment fires in a batch job, and the rep sees a prioritized lead at 8 AM the next day. That's a 22-hour gap. Research originally published by InsideSales.com and later cited by Harvard Business Review found that responding to a lead within 5 minutes produces a dramatically higher qualification rate. Twenty-two hours isn't even in the same conversation.
The hidden cost compounds fast. Reps chase noise because the score doesn't reflect fit. Hot accounts get buried under low-quality submissions. It's estimated that 70% of leads are lost due to poor follow-up, and mis-prioritization at the top of the funnel is a major driver. The fix isn't a better spreadsheet. It's enrichment data combined with event signals and lightweight scoring rules that re-score a lead continuously. Understanding the difference between real-time vs. batch data enrichment is the first mental shift required.
Key takeaway: Every hour of scoring delay reduces your odds of qualifying the lead. Batch scoring creates a structural disadvantage that no amount of rep hustle can overcome. Real-time enrichment collapses the gap from hours to minutes.
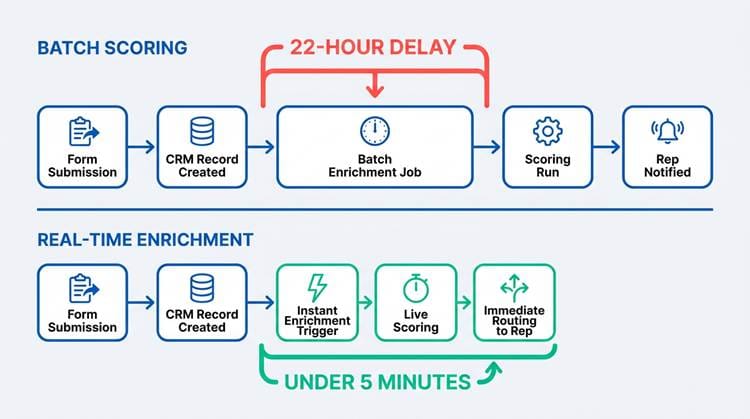
Batch scoring creates hours of lag. Real-time enrichment collapses that window to minutes.
The Signals That Actually Matter (and the Ones That Don't)
Before building a scoring model, be honest about which signals predict pipeline and which ones just feel good. Three buckets are worth separating:
The three signal categories for any lead scoring model:
● Fit (who they are): Firmographic and technographic attributes that indicate whether the account matches your ICP.
● Intent (what they're doing right now): Behavioral signals like pricing page visits, demo requests, and docs engagement that reveal buying urgency.
● Friction (how hard they'll be to close): Factors like contract complexity, procurement cycles, or missing budget signals that affect deal velocity.
Most scoring systems over-index on fit and ignore intent entirely, or treat every behavioral signal as equally meaningful. Common vanity signals that inflate scores without improving close rate include generic email opens, job title keyword matches without company context, and social profile views. A VP title at a 5-person startup with no budget is not the same as a VP title at a 300-person SaaS company in your ICP. Scoring the title without the company context is one of the most reliable ways to fill your queue with false positives. Everything that follows focuses on scoring fit and intent in real time, then using friction signals to route and sequence appropriately.
Fit Scoring with Enrichment Data: Turning a Form Fill into a Real Profile
A form fill gives you a name, an email, maybe a company name, and sometimes a phone number. That's not enough to score fit. What is data enrichment in this context? It's the process of resolving that sparse record into a full company and contact profile: industry, employee count, estimated revenue, funding stage, tech stack, HQ location, and hiring signals. All of that happens automatically, in the background, before your rep ever sees the lead.
A practical fit rubric maps enrichment fields to ICP tiers. Here's a framework you can adapt to your own ICP definition:
|
Tier |
Criteria |
Action |
|
Tier A (Route Immediately) |
Industry match, 50-500 employees, SaaS/tech vertical, Series A+, uses 2+ tools in your stack |
Instant rep assignment, Slack alert |
|
Tier B (Sequence Within 1 Hour) |
Partial industry match, 20-50 or 500-2000 employees, adjacent vertical, seed-funded or bootstrapped |
Fast-track automated sequence, rep notified |
|
Tier C (Nurture) |
Outside ICP industry, under 10 employees, no funding data, personal email domain |
Automated nurture, no rep time |
|
Disqualify/Hold |
Competitor domain, student email, job-seeker signals, existing customer |
Filtered before scoring runs |
Handling messy inputs is where most scoring systems quietly fail. Personal emails don't resolve to a company without additional signals. Typos in company names break matching. Subsidiaries often don't map cleanly to parent company data. A well-configured enrichment setup uses domain-first matching with confidence thresholds, so a low-confidence match goes to a manual review queue rather than silently scoring wrong.
Choosing Your Enrichment Source: A Pragmatic Comparison
The enrichment provider you choose directly affects scoring quality. Coverage, freshness, match rate, and latency all vary significantly across tools. For real-time inbound scoring specifically, latency matters most: if enrichment takes 30 seconds, your workflow still beats a nightly batch. If it takes 5 minutes, you may need to rethink your architecture.
|
Evaluation Criteria |
Why It Matters for Real-Time Scoring |
|
API Latency |
Enrichment must return data in under 60 seconds to keep the scoring loop under your target window. |
|
Match Rate |
Low match rates mean more leads hit your 'no data' queue, creating manual work and scoring blind spots. |
|
Data Freshness |
Stale firmographic data (old employee counts, outdated funding rounds) produces inaccurate fit scores. |
|
CRM Writeback |
The provider must write enriched fields directly to your CRM without requiring a separate middleware layer. |
|
Fallback Coverage |
Edge cases (stealth startups, global domains, personal emails) need a secondary resolution path. |
Bitscale is built to operationalize enrichment data into workflows rather than just export CSVs. For inbound scoring, that distinction matters: you want enrichment that feeds directly into scoring logic and CRM writeback without requiring a separate middleware layer. A pragmatic recommendation: pick one primary enrichment provider and add a fallback only if your match rate on edge cases (stealth startups, global domains, personal emails) demands it. Our guide to GTM data stacks is worth reading if you're evaluating options side by side.
Intent in the Moment: Scoring Real Time Leads Without Overreacting
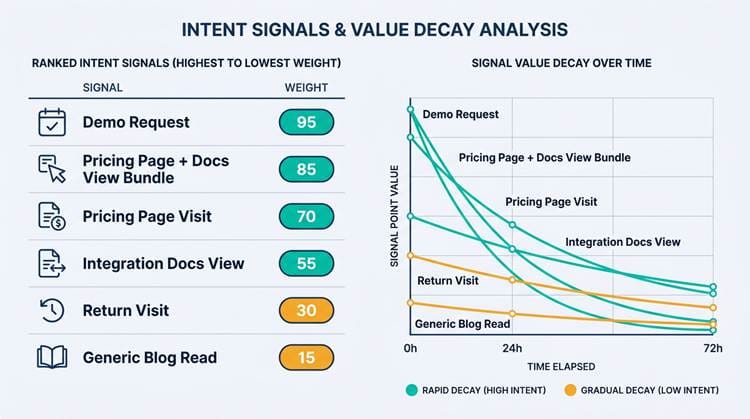
Intent signals should decay over time so your queue reflects current behavior, not last week's click.
Real-time leads are leads whose score changes based on immediate behavior. A prospect who visits your pricing page and then submits a demo request is fundamentally different from one who found you through a blog post three weeks ago. The challenge is weighting intent without letting a single "hot" click outrank a perfect-fit account with steady, sustained engagement.
The most reliable approach is requiring "intent bundles" rather than single signals. A pricing page visit alone gets 5 points. A pricing page visit plus an integration docs view plus a demo request gets 25 points. This prevents a curious competitor or a student doing research from accidentally surfacing at the top of your queue. Pair this with decay windows: intent points that fade over 24 to 72 hours, so your priority queue reflects what's happening now, not what happened last Tuesday.
Pro tip: Never let a single behavioral signal override fit scoring. Bundle intent signals together and apply decay windows so your queue stays current. A demo request from a non-ICP account should not outrank a steady-engagement ICP account.
Designing Your Scoring Logic: Simple Enough to Trust
The best inbound lead scoring models are ones your reps actually believe in. If the logic is a black box, reps will ignore the score and revert to gut feel. Start with a two-layer approach: a Fit Score (0-50 points based on enrichment data) and an Intent Score (0-50 points based on behavioral signals). Add them together for a Priority Score (0-100), then map score bands to actions, not labels.
Score bands mapped to specific actions:
● 80-100: Page a rep immediately, create a high-priority task, send a Slack alert to the account owner.
● 60-79: Enroll in a fast-track sequence within 1 hour, notify rep via email.
● 40-59: Standard nurture sequence, rep reviews within 24 hours.
● Below 40: Automated nurture only, no rep time allocated until score rises.
● Exceptions: Flag existing customers, known competitors, students, and partners before scoring runs.
Exceptions matter more than most teams realize. A competitor submitting a form to research your product will score highly on fit and intent. An existing customer requesting a feature demo shouldn't enter your new business pipeline. Build these filters into the first layer of your workflow, before scoring logic even runs. Getting this wrong doesn't just waste rep time. It corrupts your pipeline metrics and makes it harder to trust the model over time.
The Workflow Architecture: How Data Moves in Real Time
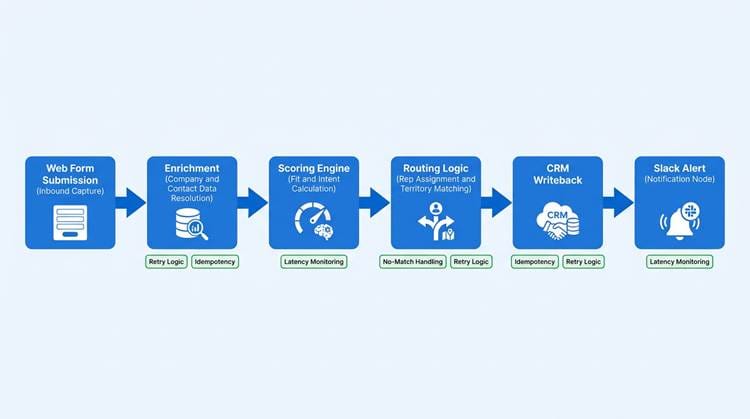
The core loop: capture, enrich, score, route, write back, and report. Every stage should complete within minutes.
The core loop runs as follows: inbound capture, enrichment, scoring, routing and alerts, CRM writeback, and reporting. Where you compute the score depends on your stack. CRM-native workflows (HubSpot or Salesforce) work well if your enrichment provider can write fields back quickly. Middleware like Zapier or Make handles lighter stacks. Platforms like Bitscale cover enrichment, scoring, and activation natively, removing the need for multiple integration points.
Reliability essentials for real-time scoring workflows:
● Build retries for enrichment API failures. A timeout shouldn't silently zero out a lead's score.
● Use idempotency keys so a lead doesn't get scored twice if a webhook fires twice.
● Define what happens when enrichment returns no match. A score of zero because enrichment failed is not the same as a score of zero because the lead is a poor fit. Tag them differently so your reporting stays honest.
● Monitor enrichment latency. If your provider's response time creeps above your target window, you need to know before reps start complaining about stale queues.
Getting Your Fields and Definitions Aligned
Scoring logic is only as reliable as the fields feeding it. Before writing a single rule, define your canonical fields: company domain, employee count, industry (using a consistent taxonomy), HQ country, tech stack, lead source, and "last high-intent event." Then normalize your picklists. "USA" and "United States" in the same country field will silently break any geography-based rule. "SaaS" and "Software as a Service" in the same industry field will do the same.
Decide ownership for each field upfront. The form tool owns lead source. The enrichment provider owns firmographics. The CRM owns deal stage and account owner. When two systems disagree on employee count, which one wins? Define this before you build, not after your first data conflict. A well-structured lead enrichment workflow documents these ownership rules explicitly.
Field ownership rule of thumb: The system closest to the source of truth should own the field. Forms own lead source. Enrichment owns firmographics. The CRM owns deal stage. Document these rules before your first data conflict, not after.
Putting It Together in Bitscale: Enrichment, Scoring, and Activation
In Bitscale, the inbound enrichment flow starts with domain resolution: the platform takes whatever the prospect submitted (company name, email domain, LinkedIn URL) and resolves it to a verified company record. Firmographic and technographic data populates automatically from there. Contact validation confirms the email is deliverable and matches the company record.
Scoring rules live in a readable scorecard that reps can review without opening a developer console. Points are assigned to enrichment fields and behavioral events, and the Priority Score is computed and written back to your CRM as a standard field. Bitscale then triggers Slack alerts for high-priority leads, assigns owners based on territory rules, and creates tasks automatically. The whole motion, from form submission to rep notification, runs in under two minutes in a well-configured setup. For teams evaluating lead data enrichment solutions, this end-to-end activation is what separates an enrichment tool from an enrichment platform.
Routing and Follow-Up: Making the Score Visible When It Matters
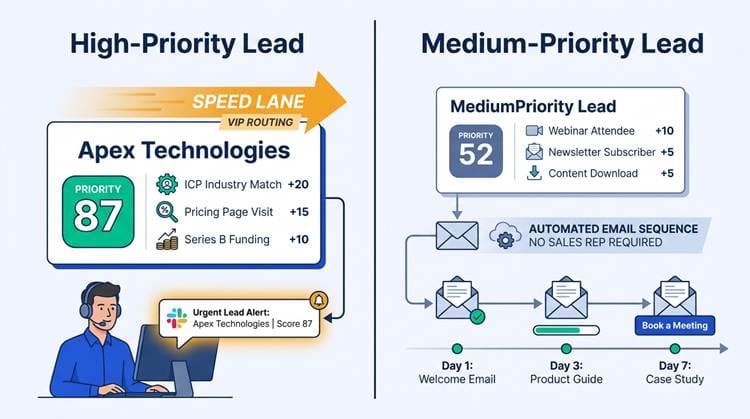
Speed lanes ensure your best leads get immediate human attention while others enter automated sequences.
Routing by priority score alone isn't enough. Territory logic and account ownership checks need to run alongside it to avoid duplicate assignment conflicts. A high-priority lead from a named account that already has an owner should go directly to that owner, not into a round-robin queue. Build that check into your routing layer before score-based assignment runs.
What reps see matters as much as how fast they see it. A score of 87 means nothing without context. Show the top three scoring drivers alongside the lead: "ICP industry match (+20), pricing page visit in last 2 hours (+15), Series B funding (+10)." That context shapes the first email or call in a way that a number alone never will. Only 44% of B2B organizations currently use lead scoring at all (Gartner, 2024), which means teams that build this visibility into their rep workflow have a real operational edge over those that don't.
Verifying It Works: A Lightweight Test Plan
Before trusting the score in production, run a backtest on your last 90 days of inbound leads. Apply your scoring model retroactively and compare score bands against actual outcomes: meeting booked, qualified, closed-won. If your Tier A leads are converting at 3x the rate of Tier C leads, the model has signal. If rates are similar across bands, the weights need adjustment.
Then do a live-fire test. Submit controlled test leads with known characteristics (a clear ICP match, a clear non-match, and a borderline case) and confirm that enrichment fires, scoring updates, routing assigns the right owner, and alerts arrive within your target window.
Ongoing guardrails to set after launch:
● Alert your ops team when a spike in "score = 0" records appears (usually an enrichment failure).
● Monitor when match rate drops below your baseline threshold.
● Flag when a single score band suddenly dominates your queue (indicates a weighting imbalance).
● Review enrichment API latency weekly to catch degradation before it affects rep workflows.
Common Pitfalls and How to Fix Them
Over-scoring job titles is the most common mistake. A "Director" title at a 10-person company with no budget is not a qualified lead. Score company fit first and role seniority second. If the company doesn't hit your minimum employee count or industry match, the title score shouldn't move the needle.
Enrichment mismatches are the second most damaging issue. A common name like "Acme Corp" might match to the wrong company entirely, sending a lead to the wrong territory rep and wasting everyone's time. Domain-first matching with confidence thresholds solves most of this. Any match below your confidence threshold goes to a manual review queue rather than scoring automatically.
Reps ignoring the score is a people problem with a systems solution. If the score doesn't affect routing, SLA expectations, or task creation, reps have no reason to trust it. Tie the score to concrete workflow outcomes from day one, and include a short explanation of why the lead scored the way it did. Scores that explain themselves get used. Scores that don't get ignored.
|
Pitfall |
Root Cause |
Fix |
|
Over-scored titles |
Title weighted without company context |
Score company fit first; title is a modifier, not a driver |
|
Enrichment mismatches |
Company-name matching on ambiguous strings |
Domain-first matching with confidence thresholds; low-confidence leads go to manual review |
|
Reps ignoring scores |
Score has no workflow consequence |
Tie score to routing, SLA, and task creation; show scoring rationale on the lead record |
|
Score inflation over time |
No regular recalibration against outcomes |
Run false positive/negative reviews every 4-6 weeks; adjust weights based on conversion data |
Measuring Impact: The Metrics That Prove It's Working
Split measurement into two layers. Operational metrics tell you the system is functioning: speed-to-lead by priority tier, time-to-first-touch, and SLA compliance (what percentage of Tier A leads were contacted within your target window). Pipeline metrics tell you the model is accurate: meeting rate, SQL rate, and closed-won conversion broken down by score band. Companies using lead scoring see a 77% increase in lead generation ROI compared to those that don't (Marketo), but that number only holds if the model stays calibrated.
Run a false positive and false negative review every four to six weeks. False positives (high-scoring leads that never converted) reveal which signals are misleading. False negatives (low-scoring leads that did convert) show which signals you're underweighting. Adjust weights based on outcomes, not intuition, and document every change so you can track what actually moved the needle.
Frequently Asked Questions
What's the difference between inbound lead scoring and traditional lead scoring?
Traditional lead scoring often applies the same model to all leads regardless of source, runs on a batch schedule, and relies heavily on manually entered fields. Inbound lead scoring is specifically designed for leads who have already expressed interest by visiting your site or submitting a form. It prioritizes speed (scoring must happen within minutes, not hours), uses enrichment data to fill gaps the prospect didn't provide, and weights real-time behavioral signals like pricing page visits alongside firmographic fit.
How fast should inbound lead scoring update to count as real time?
For practical purposes, 'real time' means the score is computed and available to your rep within 2-5 minutes of the lead submitting a form. This window allows enrichment APIs to resolve company data, scoring logic to run, and CRM writeback to complete before a rep would realistically open the record. Anything under 10 minutes is operationally useful. Anything over 30 minutes starts to lose the speed-to-lead advantage that makes real-time scoring worth building.
What enrichment data fields improve lead scoring the most?
The highest-impact fields for fit scoring are: employee count (company size), industry (using a consistent taxonomy), estimated annual revenue or funding stage, and tech stack (tools they already use). For intent layering, 'last high-intent page visited' and 'time since last visit' are the most predictive behavioral fields. HQ country matters for territory routing but has less direct impact on score quality. Job title and seniority are useful but should be weighted after company-level fit is established.
Can I do real-time lead scoring in HubSpot or Salesforce without custom code?
Yes, with some limitations. HubSpot's native scoring tool supports property-based rules and can trigger workflows on score changes, but it doesn't natively enrich records in real time. You'll need an enrichment integration (like Bitscale writing back to HubSpot fields) to make the scores meaningful. Salesforce supports more complex scoring logic through Flow or third-party tools, but the enrichment layer still needs to be external. The cleanest setup uses an enrichment platform that writes verified fields to your CRM, then lets the CRM's native workflow engine handle scoring and routing from those fields.
How do I prevent enrichment mismatches from routing inbound leads to the wrong rep?
Use domain-first matching rather than company-name matching. Email domains are far more reliable identifiers than free-text company names. Set a confidence threshold in your enrichment configuration so that any match below (say) 85% confidence is flagged for manual review rather than automatically scored and routed. Build a 'low-confidence match' queue in your CRM that a sales ops person reviews daily. This adds a small manual step but prevents the much larger cost of a rep spending 30 minutes on a lead that was matched to the wrong company entirely.
From Inbox Triage to a Real-Time System You Can Scale
Enrichment data turns an anonymous form fill into a real company profile. Real-time scoring turns that profile into a prioritized action. The technology exists and is accessible without a data engineering team. What most teams are missing is the architecture to connect the pieces and the discipline to keep the model calibrated over time.
Start small. Pick your ICP tiers, define five to eight scoring fields, and build one workflow that enriches, scores, and routes a single lead type. Run it for a week. Compare scored outcomes against what actually happened. Adjust one or two weights. Then expand. The teams that prioritize inbound leads with this kind of systematic, data-informed approach consistently outperform those relying on rep intuition and manual research, not because they have better leads, but because they act on the right ones faster. Inbound lead scoring, done well, is the operational foundation that makes every downstream motion (sequencing, routing, forecasting) more accurate.

Sanket
CEO | Co-Founder Bitscale
Sanket is the CEO and Co-Founder of Bitscale. He leads company vision and strategy, building the future of AI-driven sales intelligence for modern B2B teams. Sanket is obsessed with the intersection of AI and go-to-market, and has spent years studying how the best B2B companies find, engage, and convert customers at scale. He writes about company building, product strategy, and where AI is taking the sales industry.
Read other blogs
All Blogs
Crunchbase Review: Using Funding Signals for B2B Prospecting
Crunchbase review for B2B prospecting: funding data quality, pricing, pros and cons, and when to choose a full GTM platform like Bitscale.

G2 Buyer Intent Review: Turning Product Research Into Sales Signals
G2 Buyer Intent review: how its G2 research signals work, where account-only data limits action, pricing constraints, and when Bitscale fits better.

TechTarget Intent Data Review: Contact-Level Signals for B2B Sales
TechTarget Intent Data review: Priority Engine signals, pricing, CRM fit, and where it falls short versus GTM platforms with enrichment and automation.